
Historically, when we deploy a machine learning model into production, the parameters that the model learned during its training on data were the sole driver of the model’s outputs. With the Generative LLMs that have taken the world by storm in the past few years, however, the model parameters alone are not enough to get reliably high-quality outputs. For that, the so-called decoding method that we choose when we deploy our LLM into production is also critical.
Greedy Search

Although we would rarely use it in practice, the simplest decoding method to understand is one called greedy search so we’ll start with it. With greedy search, all we do is select the highest-probability next word in the generated sequence. This might sound like a good idea on the surface, but the problem with it is that greedy search is not optimal at generating high-probability sentences because it often misses very high-probability words that are hidden just behind low-probability words in the sequence.
Beam Search
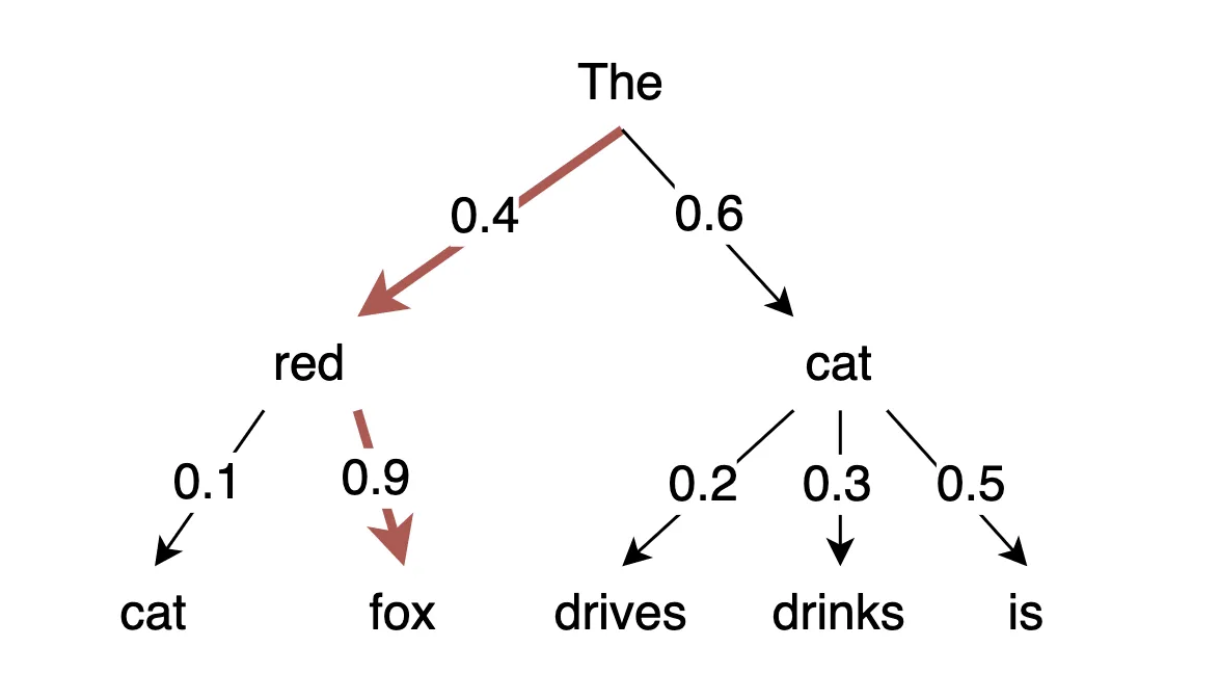
A decoding method called beam search was devised to overcome the inability of greedy search to select high-probability words that are hidden behind low-probability words. You can check out the Medium article I link to in the show notes to see visuals of this, which makes it much easier to understand, but essentially beam search looks ahead several words and, at each of those timesteps, tries out several different high-probability words. How many words beam search looks ahead is a hyperparameter you select, so too is how many words it tries out at each timestep.
As you might have guessed, computing these look-aheads can drastically increase the computational complexity of generating a sentence, but the upshot is that your model ends up outputting better, higher-probability sentences than greedy search typically does. So why doesn’t today’s Five-Minute Friday episode end right here? Well, of course that’s because beam search has its own drawbacks. Most predominantly, beam search has a tendency to generate highly repetitive sequences.
Sampling
To overcome beam search’s ugly repetitiveness, an alternative is to sample what the next word should be in a sequence. In this paradigm, the highest-probability word will be selected most frequently but not always. More specifically, using the technical terminology of probability theory, we sample words according to the probability distribution that we extract from the LLM. Output is generally more human-like and coherent when we sample although it should be noted that, as with any random sampling process, when we use sampling as our LLM decoding method it means that text generation is not deterministic (that is, unlike greedy or beam search, when we use sampling, we’ll get a different output from our LLM every time we run it). This is why, when you use, say, ChatGPT you get a different, unique response each time — even if you ask it the same question.
Two specific (and popular) decoding approaches that leverage sampling are Top-K sampling and nucleus sampling. I’ll leave it to you to dig into these if you fancy doing so; the key takeaway is that both of these sampling-based approaches to decoding support the generation of fluent, human-like outputs from a well-trained LLM.
Contrastive Search

So, that sounds pretty good, right? And sampling is! Sampling would be a fine choice for decoding your LLM in production — that is, if the far superior contrastive search hadn’t been invented. Revealed for the first time at the venerable NeurIPS conference last December, contrastive search was developed by an international public-private consortium of A.I. researchers from the University of Cambridge, Google DeepMind, the University of Hong Kong, and Tencent. I’ve provided the full paper in the show notes as well as the link to the GitHub repo for implementing contrastive search. I haven’t yet been able to think up an intuitive way of describing the mathematics of contrastive search that are detailed in the paper, but the essential takeaway from this episode is that — from our experience training and deploying generative A.I. models at my machine learning company Nebula — using contrastive search results in by far the best, most human-like outputs from LLMs. Wherever you have the opportunity to use contrastive search in production (the services that make it easy to deploy LLMs increasingly include an implementation of it), you should! Try it out yourself and I’m confident you’ll be impressed.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.